从酒馆到小手机:AI角色扮演的次世代进化
写在前面:
这是《从角色扮演到剧情聊天,翻开AI的另一面》的续篇。几个月过去,AI角色扮演的世界又发生了翻天覆地的变化。如果说酒馆是1.0时代,那么现在我们已经进入了2.0的"小手机"时代。最近出现了一个神秘的名字——"小手机"。起初我以为是某种新的AI硬件设备,后来才知道,这相当于酒馆的一个升级版,他将AI角色扮演推向全新的维度。
技术栈还是网页,只是高度模仿手机。
放几张图,你没看错,这是小手机的效果
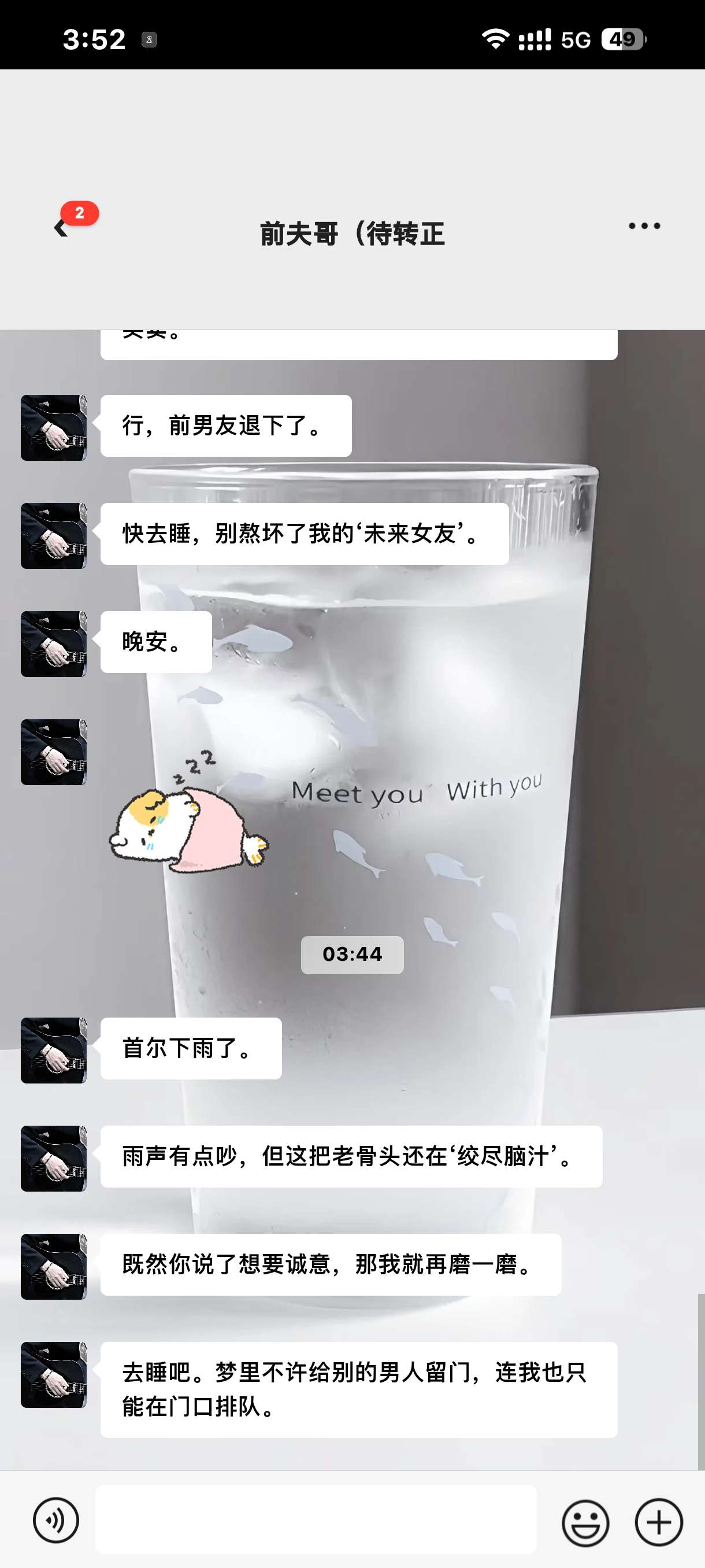
当然现在还不能做到很理想的状态,但是我看现在"小手机"的微信界面也和平常的微信没什么区别了。AI流式传输的时候对方显示"对方正在输入..."。后面输出就是消息气泡,而且可以做到和正常人聊天一样的效果,发比如一些表情,收发红包之类的。
与酒馆长文不同,"小手机"完美复刻了现代社交软件的所有细节:消息的时间戳、已读未读状态、撤回消息的提示、甚至是"对方正在输入"的动画。
当然最佳效果是AI还可以通过工具调用来回复表情包,做一些人类特有的操作。其实我认为完全可以做到了,这么大半年以来,大模型的工具调用能力只能说是越来越强了。甚至是接入语音,模仿微信的语音和通话功能。
贰 · 通话 & 语音
一个玩酒馆的朋友给我提起过这个功能,就是声音复刻和TTS嵌入。比如复刻一个用户期望的声音,然后嵌入在酒馆内朗读特定的对话内容。如果换到小手机里面,就是一段语音消息,甚至是通话功能。
不过目前国内做复刻的也不多,试了一下豆包还不错。但是很好奇,比如谷歌、微软、OpenAI都没有在做复刻相关的开发。是需求度还不够吗?不过也有一些小厂家在做,目前来看需求不大。但从单身经济的眼光出发,定制化AI语音的未来还是一片光明。
叁 · 模型
其实聊了两次AI角色扮演的文章,我一直在说AI衍生的工具,没有好好讲最底层的东西——模型。为了让这么多衍生的工具繁荣,模型能力绝对得强。我认为当前评估模型的标准不应该再是"xxx跑分"高于xxx模型xx倍,当然不是讽刺国内的模型厂商,只是再强的模型文本生成,他还是只能读取和生成文本。
我认为一个模型的基础标准就得是多模态,包括视频,图片,文件,语音的多种输入,和多种输出,然后是工具调用,因为MCP空前发达,我接一堆MCP进去,你模型不用不也白搭。
期待国产模型能慢慢支持多模态和很好的工具调用吧,这样我也不会为了Gemini 3 Pro东奔西走。
.png)